Dynamic provisioning of NVIDIA Spectrum-X Ethernet with SR-IOV and NV-IPAM on CNCF Kubernetes

AI bottlenecks? Don’t automatically blame the hardware
In the world of AI, performance is everything. The ongoing pursuit for higher performance and greater scale creates significant challenges for infrastructure professionals like ourselves, as new products emerge and architectures evolve to take full advantage of them.
Recently, I was part of a project in the public sector to revamp an AI training environment that was not meeting the needs of its users. The hardware was great: Plenty of NVIDIA HGX-based 8-GPU NVIDIA Hopper NVL servers with a dedicated NVIDIA BlueField-3 DPU, 400Gb/s bandwidth to each GPU, and scaled with the NVIDIA Spectrum-X Ethernet networking platform for accelerated RDMA over Converged Ethernet (RoCE) networking.
The software stack needed some updates. An outdated Red Hat OpenShift cluster was running an earlier version with Spectrum-X Ethernet software stack predating OpenShift compatibility. This required some less-then-ideal workarounds to make things work, like running training jobs as privileged pods on the host network. It was also very basic for end users, with no friendly user interface to schedule jobs or monitor progress.
You can see how organizations get stuck in situations like this. Deploying and configuring a solution stack manually requires installing multiple software packages per worker, flashing and configuring firmware on every network card — with multiple reboot cycles along the way. Having significant sunk costs invested to get to a working infrastructure, even a sub-optimal one, it’s tempting to stay put.
But this customer knew there was a better paradigm for configuring their AI environments. We're moving away from the older paradigm of setting everything up on each host OS and then running the AI containers on the host network to leverage all the parts we've set up; instead we’re moving all these things into Kubernetes Operators, Kubernetes-native resources and dynamic composition, so that things actually become easier to manage, automate and secure.
Let’s dive in.
A fresh start: aligning to the NVIDIA reference architecture
So: the customer decided they wanted a do-over and planned a transition to an architecture fully in line with the NVIDIA Reference Architecture for AI on Spectrum-X Ethernet, which meant BlueField going to vanilla CNCF Kubernetes on Ubuntu.
Next would be moving away from privileged containers, and deploying an AI management system that users would genuinely value.

If you’re unfamiliar with it, the NVIDIA Spectrum-X Ethernet platform is a revolutionary networking solution for enterprises and hyperscalers to accelerate AI workloads and data over Ethernet.
Spectrum-X Ethernet brings an advanced array of capabilities designed to address the scalability and performance challenges associated with deploying RoCE for AI at scale:
- Adaptive Routing with weighted ECMP
- Congestion Control, which prevents in cast congestion caused by elephant flows
- Performance Isolation to provide networking QoS
When combined with Bluefield-3 SuperNICs, you get additional benefits such as DDP, out-of-order packet handling and RoCE congestion control from the sender side.
These Spectrum-X Ethernet technologies can provide a considerable performance boost (up to 1.6x) for AI workloads at scale compared to unoptimized Ethernet, making it a compelling option for enterprises and hyperscalers.

Putting Spectrum-X Ethernet to work, without the toil
Spectro Cloud Palette supports Spectrum-X and can provision entire AI-ready Kubernetes clusters from scratch onto bare metal hardware.
First, we leverage Canonical MAAS to PXE boot bare metal servers and deploy Ubuntu with Kubernetes through our Cluster API provider for MAAS.
Palette then prepares the hosts with all the necessary NVIDIA DOCA software, flashes the desired firmware onto the NVIDIA Bluefield-3 SuperNICs and configures them for Spectrum-X Ethernet.
Since multiple node reboots are required during this node preparation, Palette maintains a taint on these Kubernetes worker nodes while the node preparation process is ongoing. Once nodes complete this process, the taint is automatically removed and Kubernetes can begin scheduling workloads onto them.
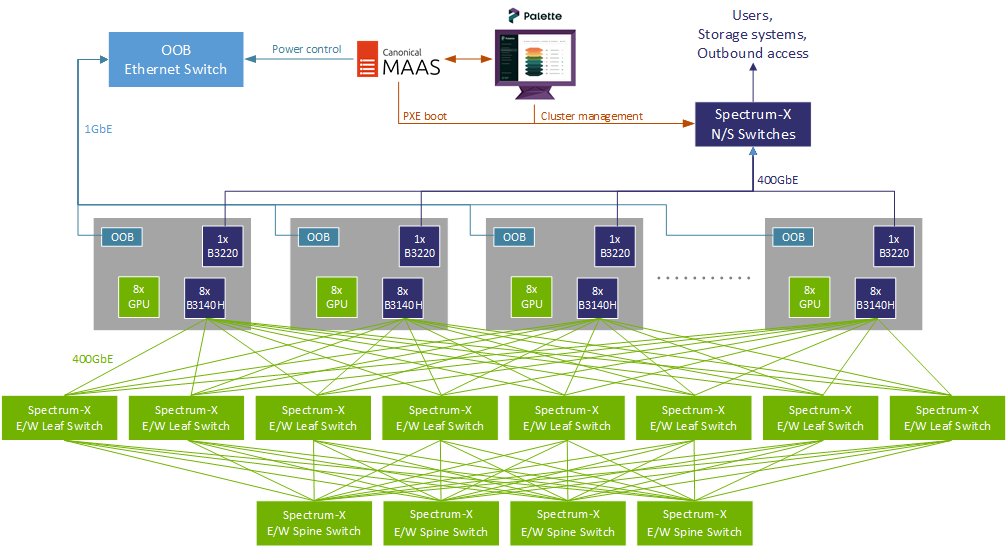
Unpicking Layer 3 networking challenges
The way that Spectrum-X Ethernet maintains RoCE performance at scale is by using a Layer 3 routed design. Instead of a flat Layer 2 network that would suffer from broadcast and ARP traffic when interconnecting thousands of nodes and tens of thousands of NICs, Spectrum-X Ethernet uses a pure Layer 3 network where every link only ever sees two IP addresses: the IP of the NIC on the server and the IP of the port on the switch. Each IP on each switchport acts as the default gateway for each NIC in the server. Layer 3 routing in the switches then allows every NIC to talk to every other NIC. RoCE finally delivers RDMA capabilities on top of that, so that GPUs can directly talk to each other.
In the original OpenShift cluster, this was implemented with Netplan files for the host OS, which meant that AI workload containers had to be scheduled with hostNetwork: true in order to use the Spectrum-X Ethernet RoCE network. That required running the pods with elevated permissions and goes against Pod Security Standards best practices.
When initially trying out this same model on the vanilla CNCF Kubernetes cluster, we also found that c10d in a PytorchJob had significant trouble resolving the master service name in which to bind to an IP address. There’s a whole array of things that contribute to this not working well when running on the host network, with none of the workarounds really being viable for a Kubernetes cluster. So even more reason to redesign the whole thing into something much more Kubernetes-native, which is what we did.
A K8s-native approach with SR-IOV and NV-IPAM
The NVIDIA Network Operator has an example for the NVIDIA Magnum IO GPUDirect support that uses the SR-IOV device plugin to inventory NICs, and the HostDeviceNetwork resource to assign them to pods as additional networks.

However, the example uses Whereabouts for IP addressing, which will not line up with the Layer 3 routed IP schema configured in the Spectrum-X Ethernet switches.
Fortunately there is the NVIDIA NV-IPAM plugin that does support carving up the IP space in lots of small /31 segments and statically assigning each one to a specific host so everything lines up correctly.
In our recent project, a conversion script was created by NVIDIA to convert the Netplan files used previously at the host level to CIDRPool resources for NV-IPAM. A total of 8 HostDeviceNetworks are created this way, each with its own CIDRPool. An example of the first one:
apiVersion: mellanox.com/v1alpha1
kind: HostDeviceNetwork
metadata:
name: rail-1
spec:
networkNamespace: default
resourceName: "nvidia.com/rail-1"
ipam: |
{
"type": "nv-ipam",
"poolName": "rail-1",
"poolType": "cidrpool"
}With the rail-1 CIDRPool looking like this
apiVersion: nv-ipam.nvidia.com/v1alpha1
kind: CIDRPool
metadata:
name: rail-1
namespace: nvidia-network-operator
spec:
cidr: 172.16.0.0/15
gatewayIndex: 0
perNodeNetworkPrefix: 31
routes:
- dst: 172.16.0.0/15
- dst: 172.16.0.0/12
staticAllocations:
- gateway: 172.16.0.1
nodeName: worker-gpu-0
prefix: 172.16.0.0/31
- gateway: 172.16.0.3
nodeName: worker-gpu-1
prefix: 172.16.0.2/31
...
- gateway: 172.16.1.61
nodeName: worker-gpu-62
prefix: 172.16.1.60/31
- gateway: 172.16.1.63
nodeName: worker-gpu-63
prefix: 172.16.1.62/31To populate the nvidia.com/rail-1 resource with the first SuperNIC in every node, we configured the sriovDevicePlugin section of the NicClusterPolicy with a resourcelist:
spec:
sriovDevicePlugin:
config: |
{
"resourceList": [
{
"resourcePrefix": "nvidia.com",
"resourceName": "rail-1",
"selectors": {
"isRdma": true,
"pciAddresses": ["0000:7a:00.0"]
}
},
...
{
"resourcePrefix": "nvidia.com",
"resourceName": "rail-8",
"selectors": {
"isRdma": true,
"pciAddresses": ["0000:42:00.0"]
}
},
]
}Once all configured, training jobs can simply request the GPUs and NIC rails for each host as an extended resource:
apiVersion: "kubeflow.org/v1"
kind: "PyTorchJob"
metadata:
name: "pytorch-dist-nccl"
namespace: "default"
spec:
pytorchReplicaSpecs:
Master:
template:
metadata:
annotations:
k8s.v1.cni.cncf.io/networks: rail-1, rail-2, rail-3, rail-4, rail-5, rail-6, rail-7, rail-8
spec:
containers:
- name: pytorch
resources:
limits:
nvidia.com/rail-1: 1
nvidia.com/rail-2: 1
nvidia.com/rail-3: 1
nvidia.com/rail-4: 1
nvidia.com/rail-5: 1
nvidia.com/rail-6: 1
nvidia.com/rail-7: 1
nvidia.com/rail-8: 1
nvidia.com/gpu: 8This worked beautifully!
Pytorch had no problem rendezvousing with all the workers and containers were able to take full advantage of the RDMA devices.
Now we can run standard unprivileged containers and use Kubernetes-native practices to bring in dedicated hardware through requesting them in the resources: {} section of the container.
This approach will likely also influence the next version of the NVIDIA Reference Architecture for AI on Spectrum-X Ethernet, as it provides a better foundation for controlling all components of the stack through Kubernetes, instead of inheriting a network configuration from the underlying host OS.
The next step will be to adopt use of the nic-configuration-operator, which moves even more configuration away from the host and into Kubernetes-managed resources.
A benefit of all this is that as more configuration is managed via Kubernetes, it becomes easier to manage incremental change as well, such as version upgrades. Want to try out a new setting for your NICs, or a new firmware version? It would will be easier to try on a few nodes if you can manage this via Kubernetes, and roll back if the results aren’t satisfactory.
Tackling the user experience with NVIDIA Run:ai
As the icing on the cake, we installed NVIDIA Run:ai over the top of the stack so that users actually have a proper platform to manage their AI workloads. NVIDIA Run:ai is an AI workload and GPU orchestration platform that helps organizations maximize GPU utilization, streamline resource allocation, and simplify the management of AI workloads — all while giving developers a smoother, more productive experience. Spectro Cloud Palette has ready-to-go cluster profiles for NVIDIA Run:ai, so installation is very straightforward.
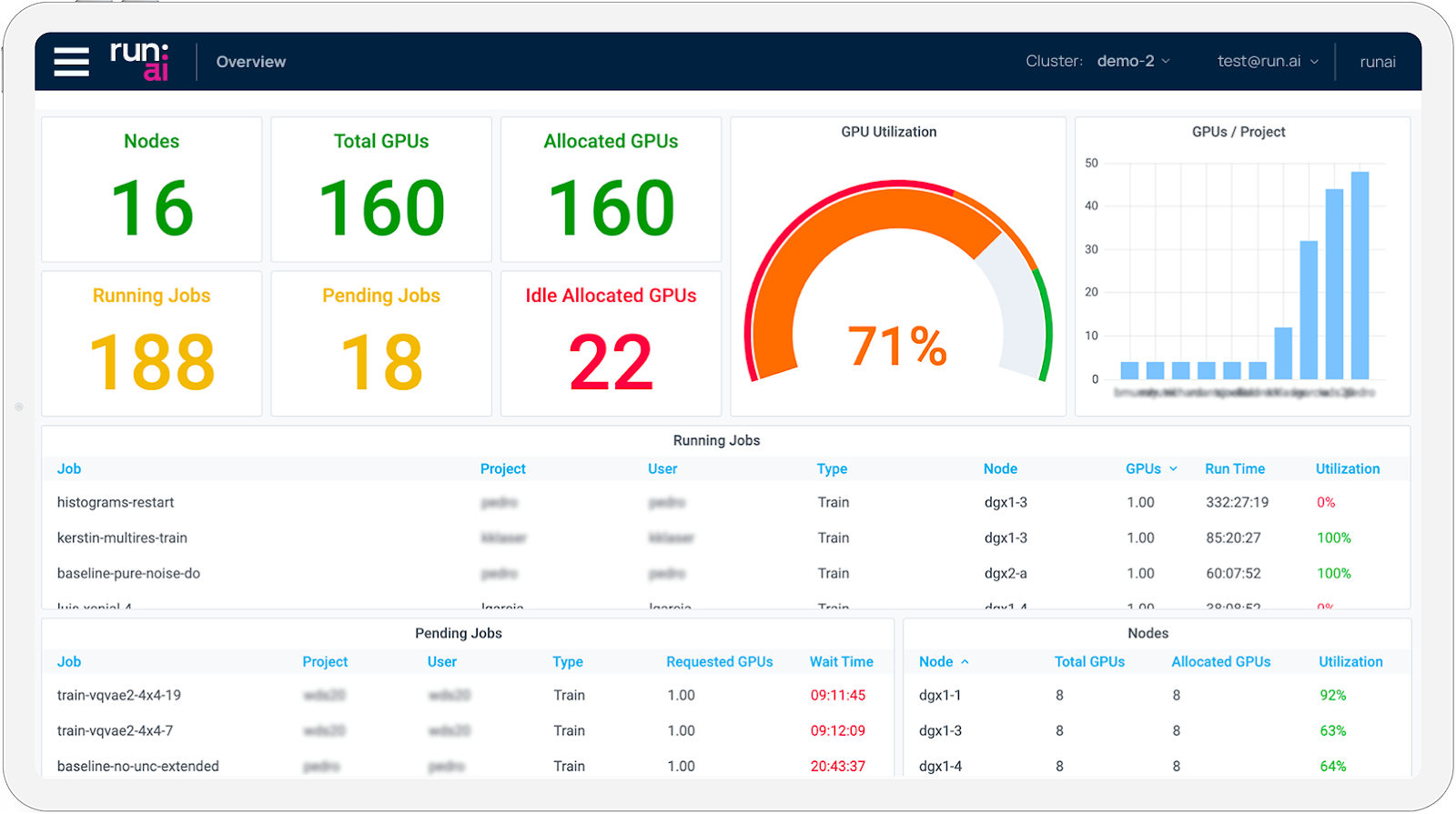
Now users can simply interact with NVIDIA Run:ai to define, manage and monitor their training jobs — no more fiddling around with kubectl.
Taking Spectrum-X Ethernet to new use cases
Our customer is already seeing the value from their new Kubernetes-native approach to provisioning and managing AI networking. As for us, we’re already looking at the next steps for Spectrum-X Ethernet infrastructures, including tackling multitenancy and smaller configurations with 1:2 ratios of SuperNICs to GPUs.
In the meantime, you can learn more about Spectrum-X Ethernet here, or come talk to us at NVIDIA’s GTC conference in Washington DC, or at KubeCon AI Day in Atlanta.